목차
I. 논문 정보
II. 리뷰 내용
0. Abstract
1&2. Introduction & Related Works
3. Graph-based Hybrid Recommendation System
4. Empirical Experiments and Performance
5. Conclusion and Future Works
III. 고찰
** 리뷰 내용 중 +) 의 경우, 논문에서 발췌한 내용이 아니라 내 의견 또는 다른 참고 자료임
I. 논문 정보
- 원제: GHRS: Graph-based Hybrid Recommendation System with Application to Movie Recommendation
- 출간연도: 2022
- 저널: Expert Systems with Applications, Volume 200, 15 August 2022, 116850
- DOI: http://dx.doi.org/10.1145/2740908.2742726
- 선정 이유: paperswithcode movielens 100k에서 가장 좋은 성능을 보이고 있는 모델
II. 리뷰 내용
0. Abstract
- 사용자들의 평점 유사도와 관련한 그래프 기반 모델을 사용한 추천 시스템 방법을 제안하는 논문
- 평점 유사도 뿐만 아니라 사용자의 인구통계학적 정보 및 위치 정보를 결합하여 사용
- 특징 추출에 Autoencoder 사용. 사용자 클러스터링 적용
- 무비렌즈 데이터 세트에 대해 실험 수행 (100k, 1M)
- 추천 정확도에서 기존 알고리즘보다 우수. Cold-start 문제에서도 유의미한 결과
1&2. Introduction & Related Works
- side information은 평점과 매우 관련있으나, 이전 DL 기반 추천 시스템 연구는 유저나 아이템의 side information과 상관 없이 모델링함.
- 본 연구에서는 user-item 비선형 표현을 학습하고 side information으로 cold-start 문제를 해결하는 하이브리드 접근 방식을 제시함.
- DL 기반의 추천 모델 중 AE 기반의 추천 모델에 대해 리뷰함
- AE based CF model: AutoRec, CFN, CDAE, multi-VAE, multi-DAE 등이 있었음. sparse 데이터에 대해서는 예측 정확도가 낮고, integer가 아닌 평점은 예측하지 못하는 결점이 있었음.
- feature Representation learning: CDL, SDAE, CDR, autoSVD++, HRCD 등이 있었음. cold-start problem을 해결함.
비선형 표현을 배우고 side information을 통합하여 cold-start 문제를 해소하기 위해 AE를 사용한 하이브리드 방식을 제안함. 유저의 선호, 유사성, side info를 하나의 행렬에 통합
ratings
- implicit feedback
- a global default rating is zero
- We used this matrix to find similarity between users’ preferences.
3. Graph-based Hybrid Recommendation System
- notation
- architectural view, algorithmic steps
- graph-based features
- clustering methods
3.0. Basic notations
n 명의 유저, $$ 𝑈 = {𝑢1*, ..., 𝑢𝑛*} $$
m 개의 아이템, $$ 𝐼 = {𝑖1*, ..., 𝑖𝑚*} $$
유저 아이템 쌍으로 이루어진 행렬, 𝑟𝑢𝑖 는 유저 u와 아이템 i의 implicit feedback으로 이루어짐. global default rating: zero이며 이 행렬을 유저 선호 사이의 유사성을 찾는 데에 활용
$$ 𝑅 = 𝑈 ×𝐼 $$
유사도 그래프를 생성한 뒤, 이 그래프에서 (n, g) 행렬을 구성하는 특징을 추출
$$ 𝐹𝑔 = {𝑓1*, ..., 𝑓𝑔*} $$
유저의 side information, $$ 𝐹𝑢 = {𝑓1*, ..., 𝑓𝑢*} $$
아이템의 side information $$ 𝐹𝑖 = {𝑓1*, ..., 𝑓𝑖*} $$
=> 결합된 특징 행렬 (n, g+s)
3.1. Architecture

GHRS는 7 단계로 구성됨
- 사용자를 노드로 하는 그래프 구축. 두 사용자는 유사도에 따라 연결되며, edge는 비슷한 평점을 가진 항목의 비율이 𝛼% 이상인 사용자 쌍을 연결함
- 각 사용자에 대한 유사도 그래프에서 PageRank, 정도 중심성, 근접성 중심성, 최단 경로 간 중심성, 로드 중심성, 그래프에서 각 노드 이웃의 평균 정도 등의 그래프 특징을 추출
- 세 번째 단계에서는 성별, 나이와 같은 부가 정보와 그래프 기반 특징을 결합하여 하나의 행렬 생성.
- side information으로 이루어진 (n, s) 행렬
- 유사도 행렬에서 추출한 특징으로 이루어진 (n, g) 행렬
- → 둘을 결합한 (n, g+s) 행렬 준비
- 위에서 결합한 행렬에 AE를 적용하여 새로운 특징을 추출함
- 새로운 특징 k개로 이루어진 (n, k) 데이터에 K-Means 알고리즘을 적용하여 사용자를 적절한 수의 그룹으로 그룹화함
- (사용자, 클러스터) 행렬과 (클러스터, 아이템) 행렬을 얻음
- 새로운 사용자는 인코딩하여 클러스터에 할당하고, 아이템은 다른 아이템과의 유사성을 기반으로 새로운 클러스터에 대한 평점을 계산함
- 클러스터의 평균 평점을 이용하여 유저의 모든 아이템에 대한 예상 평점을 계산
알고리즘

유사도
두 유저에 대하여 같은 아이템에 대해 같은 평점을 내린 아이템의 개수를 의미. 비율이 a 보다 클 때 둘의 관계는 1 아니면 0.
CI 행렬은 이렇게 만든다
item i, cluster c 에 대해서
- cluster c에 속한 user들 중 item에 대해서 평가한 유저가 있는 경우: 이들에 대한 평균
- cluster c에 속한 user들 중 “유사한” item에 대해서 평가한 유저가 있는 경우: 이들에 대한 평균
- 없는 경우: cluster c에 속한 모든 유저의 평균
그래서
유저의 전체 평점은 행렬의 곱으로 풀어낸다.
3.2. Graph-based Features
유사도를 대표하는 그래프 특징과 수식을 리뷰
- Page Rank: 노트의 과도적 영향이나 연결성을 평가하는 알고리즘. 웹 페이지를 랭킹하기 위해 고안된 알고리즘.
- Degree Centrality: 한 노드에서 들어오고 나가는 관계의 수를 측정하는 것으로 개별 노드의 인기도를 찾는 데 사용할 수 있음. 정보를 가장 효율적으로 확산할 수 있는 노드를 감지할 수 있음. d(v, u)는 가장 짧은 거리로, 점수가 클수록 다른 노드와의 거리는 짧아짐.
- Closeness Centrality: 그래프를 통해 정보를 효율적으로 확산시킬 수 있는 노드를 감지하는 방법(Freeman, 1979). 노드 u의 근접성은 다른 노드 n-1 개에 대한 평균 근접성(그래프 내 거리)을 측정. 거리의 합은 그래프 노드 수에 따라 달라지므로, 근접성은 가능한 최소 거리 𝑛 - 1의 합으로 정규화됨

- Betweenness Centrality: 한 노드가 그래프의 정보 흐름에 미치는 영향력을 감지하는 데에 사용되는 요소. 그래프의 한 부분과 다른 부분으로 연결되는 다리 역할을 하는 노드를 찾는 데에 자주 사용됨. 최단 경로에 자주 위치할수록 연결 중심성이 높아짐.

- Load Centrality
- Average Neighbor Degree: 각 노드의 이웃 평균 거리.
3.3. User Clustering
- 유저는 특정 클러스터에 속하게 됨.
- 아이템에 대한 클러스터 점수는 u-i 쌍의 추정된 평점으로 간주됨.
- AE로 추출한 유저의 특징은 K-Means 알고리즘에 의해서 그룹화됨. Elbow 와 Average Silhouette 알고리즘으로 최적의 클러스터 개수를 찾음.
K-Means Algorithm
간단한 반복 그룹화 알고리즘. K개의 클래스와의 거리를 구해 분산을 최소화하는 클러스터의 중심을 찾음.
- Elbow Method: 클러스터의 개수에 따라 explained variation를 플롯팅하는 방법으로 적절한 클러스터 개수를 찾기 위한 방법. elbow point 이후의 클러스터 개수는 오버피팅될 수 있으니 주
- Average Silhouette: 군집화의 질을 측정하는 방법. 각 클러스터에 객체가 잘 분배되었는지를 측정. 값이 높을 수록 의미있는 군집화를 말함.
4. Empirical Experiments and Performance
4.1. Dataset
- MovieLens 100K (100,000 ratings 𝑅 ∈ {1*,* 2*,* 3*,* 4*,* 5}, 1,682 movies (items) rated by 943 users
- MovieLens 1M (1,000,209 ratings 𝑅 ∈ {1*,* 2*,* 3*,* 4*,* 5} of approximately 3,900 movies made by 6,040 users)
- 유저 특징: 직업과 성별, 나이가 있음 (많지 않음)
- 10M 데이터에는 유저의 인구통계학적 정보가 없어서 사용하지 않음.
4.2. Features Statistics
- 두 종류의 특징 사용 side information and features extracted from the similarity graph between users. 인구통계학적 데이터는 명목형으로 원핫 인코딩되어 사용. 그래프 특징과 결합
- 그래프 생성 시에 a 라는 파라미터를 사용함. 이는 두 유저의 관계를 정의할 때 전체 영화대비 몇 개의 영화를 공유할 때에 관계가 있다고 판단할지를 정하기 위한 역치 값으로 percentage임. 𝛼 = 0*.*015를 사용함.
- 그래프 특징: PR (page rank), CD (degree centrality), CC (close- ness centrality), CB (betweenness centrality), AND (average neighbor degree), and LC (load centrality)
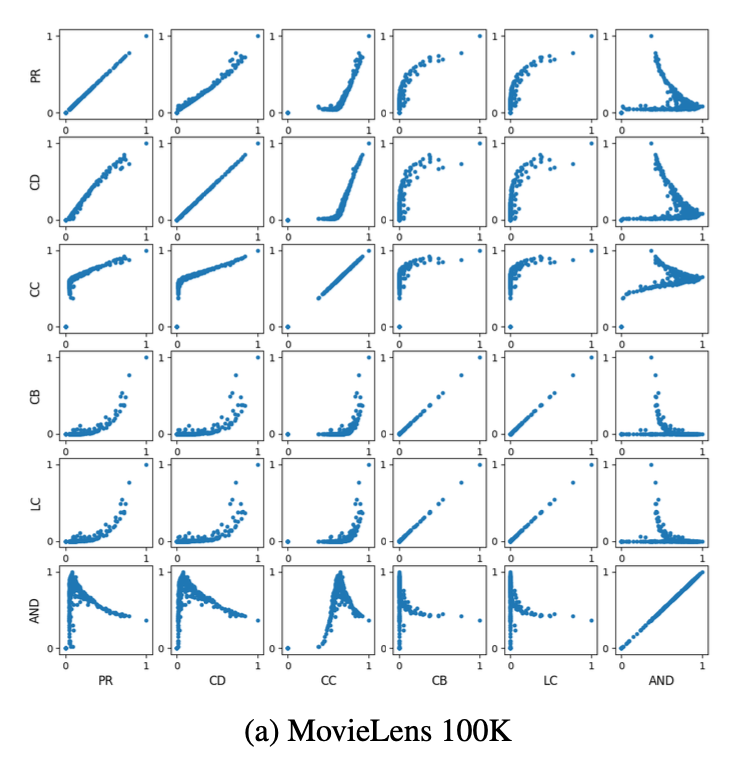

- PR과 CD와 같은 중심성 지표가 다른 지표에 비해 상관 관계가 높은데, 연결 정도가 높은 사용자는 많은 경우에 연결될 가능성이 높다는 것을 의미
4.3. Performance Metrics
cv
- 10-fold cross-validation on MovieLens 1M dataset
- 5-fold cross-validation on MovieLens 100K dataset
metrics
- Root Mean Squared Error (RMSE) - 평점
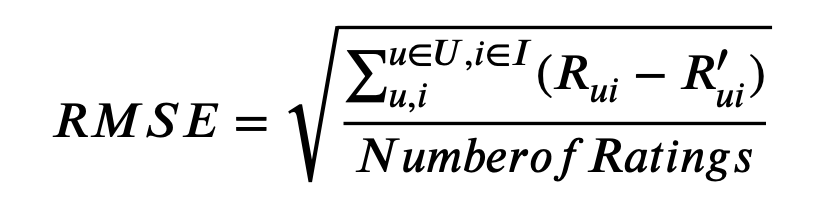
Precision(전체 추천 중 맞는 추천), Recall(전체 정답 중 맞는 추천) - 평점에 역치 적용하여 2클래스

4.4. Impact of similarity graph size
a 값을 다양하게 조정하여 그래프 크기에 따른 RMSE 차이를 확인. 최적의 값은
- 0.01 on MovieLens 1M dataset
- 0.005 on MovieLens 100K dataset

4.5. Dimension Reduction
- 5-layer Autoencoder
- activation function of all layers is ReLU
- Both input and output vector size
- 35 for MovieLens 100K
- 36 for MovieLens 1M.
- Hence, Adam seems to be the best option for the optimizer.
- net regularization applied


4.6. Number of Clusters
- Elbow method and Average Silhouette method
- 8, 9 clusters selected

4.7. Results and Comparison with Other Methods
Best setting results

MovieLens 1M에서는 가장 낮은 RMSE를 보였음. (papers with code에서는 다른 모델들의 RMSE가 더 낮다고 함)

5. Conclusion and Future Works
- 주요 제안 내용: 유사도 그래프의 노드로서 사용자 간의 유사도를 기반으로 사용자 간의 관계를 찾고, 이를 사용자의 부수 정보와 결합하여 콜드 스타트 문제를 해결하는 것
- 여기에 오토인코더를 적용하여 상관관계가 낮고 더 많은 정보를 가진 새로운 저차원 특징을 추출
- 이를 통해 최종 클러스터링 단계의 정확도를 높이고 시간을 단축함
- 최종 실험과 다른 방법과의 비교를 통해 선택한 데이터 세트에 대해 경쟁력 있는 결과를 얻었으며, MovieLens 1M 데이터 세트에서 최상의 결과를 개선
future works
- 아이템 간의 유사도를 찾기 위해, 아이템 속성에 대한 연구가 필요함
- 유사도 그래프에서 다른 더 많은 특징을 개발하고 출할 수 있음
- 오토인코더 구조에 관한 추가 연구
- 사용자 클러스터링 방법 고도화
- 사용자 demographic feature가 많은 데이터로 재평가 필요
III. 고찰
정리
- 모델이 아니라 추천 “시스템” 이다 (AE가 특징 추출에 이용되긴 함)
- 성능이 크게 개선되지는 않았다
- 추천 문제를 위한 다양한 데이터 세트에 대해서 그래프 특징을 추출하여 성능 향상을 기대해볼 수는 있겠다.
- 코드가 공개되지 않았고, 알고리즘의 복잡도가 높은 데에 반해 설명이 불충분하다.
의견
얻을 수 있는 점
- 그래프 기반의 특징을 추출하여 추천에 활용할 수 있음
- side-information의 결합을 통한 Cold-start 문제의 해결 (이미 CDAE에는 있지만)
- 결국에는 평균가지고 하는 거다. → 다른 시스템의 backup으로는 활용할 수 있음 (cold-start 평균처리)
아쉬운 점
- 시스템 전반적으로 복잡해졌고, 이전 시도들을 잘 묶어놓은 것에 불과한 듯
- figure도 많고, 설명도 나름 많은데, 오히려 핵심인 부분은 명시적으로 설명이 안되어 있다. 특히 아이템의 유사성을 계산하고 어떤 것이 유사한지를 결정하는 내용이 없어서 당황스러웠다.
- side-information에 의해 cold-start가 해결하였다고 했지만, 실제로 이에 관한 실험이 없어서 학습이 잘 된 것인지 그렇지 않을 것인지 알기 어려움
- 알고리즘과 코드를 상세히 제공하지 않고 이전 연구에 대한 리뷰가 중점적임
- 결국에는 평균가지고 하는 거다.
'인공지능 > 추천 시스템' 카테고리의 다른 글
| [paper] GPT4Rec 논문 리뷰 (0) | 2023.07.27 |
|---|---|
| [추천시스템] nDCG가 도대체 뭐지? 예제를 통해 알아보자 (3) | 2023.07.19 |
| [논문리뷰] CORE: Simple and Effective Session-based Recommendation within Consistent Representation Space (2) | 2023.05.20 |
| [논문리뷰] AutoRec: Autoencoders Meet Collaborative Filtering (3) | 2023.05.19 |
| [토이프로젝트] 코사인 유사도 기반의 아이템 추천 API 만들어보기 (0) | 2023.04.09 |


