갑자기 온라인 쇼핑 플랫폼을 보는데, 아이템 유사도 기반의 일련의 추천 API를 구현하는 것은 어렵지 않을 것 같다는 생각이 들었다. 개발은 서툴기에 아주 간단한 거니까 한 번 해보자라는 마음으로 아래와 같은 알고리즘, API를 구성해보았다.
개발 환경
- 사용한 데이터: mnist fashion data 이미지 데이터
- API 구현: flask
알고리즘
1. API의 파라미터로 전체 패션 아이템 중 하나를 선택하여 그 key를 전달한다.
2. 전체 패션 아이템과 선택한 아이템의 코사인 유사도를 계산한다.
3. 코사인 유사도가 높은 순으로 정렬한다. (ranking)
4. 유사도가 높은 것 중 Top N개에 대한 key를 API로 응답한다.
5. key를 받아, 유사한 아이템이 무엇인지 확인해본다.
위와 같은 알고리즘을 구성하면, 아주*무한대로 간단하지만 아래와 같은 시스템을 만들 수 있음. 데이터 베이스와 앱이 잘 작동하고 있다는 전제 하에..


구현은 정말 간단하다. API는 다음과 같이 구성할 수 있다.
app.py
from flask import Flask, jsonify, request
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import tensorflow as tf
app = Flask(__name__)
@app.route("/recommend", methods=['GET'])
def get_similar_images():
#images = request.args.get('name')
images = get_train_images()
target_index = int(request.args.get('target_index'))
rank = int(request.args.get('rank'))
images_1d = images.reshape(
(images.shape[0], images.shape[1]*images.shape[2]))
# get similarity
scores = cosine_similarity(
images_1d, [images_1d[target_index]])
sorted_score_index = np.argsort(np.squeeze(scores))[::-1]
return jsonify(
message=np.array2string(sorted_score_index[1:rank+1]))
def get_train_images():
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, _), (_, _) = fashion_mnist.load_data()
return train_images
terminal에서 flask를 환경에 설치한 뒤, 아래와 같이 api 서버를 띄운다.
(env) $ pip install flast
(env) $ FLASK_APP=app3.py FLASK_DEBUG=1 flask run
API 요청은 다음과 같이 보낼 수 있다. jupyter notebook으로 하면 이미지도 바로 열어서 볼 수 있으므로 좋다.
import requests
rank = 50
r = requests.get(
f'http://127.0.0.1:5000/recommend?target_index=111&rank={rank}')
similar_indexes = np.fromstring(message[1:-1], dtype=int, sep=' ')
similar_indexesarray([35541, 15081, 18339, 43917, 17899, 29768, 30034, 20174, 8776,
53939, 21342, 1685, 9145, 17389, 18094, 57317, 54745, 23744,
10119, 45365, 55314, 19318, 52275, 46536, 1079, 42360, 23432,
52468, 21894, 20578, 32024, 18352, 30257, 38284, 5539, 42774,
7468, 40258, 59514, 15693, 39308, 16721, 23838, 53552, 19918,
36403, 47630, 18502, 11591, 24182])
요청을 보낸 111번째 이미지는 아래와 같은 앵클 부츠이다.
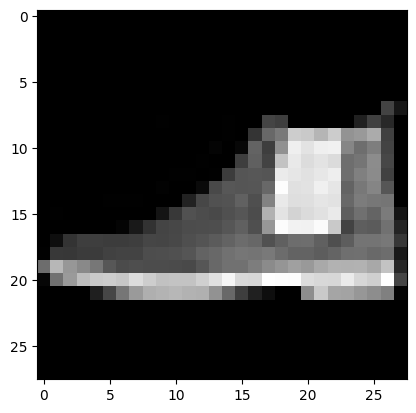
이미지를 확인해보려면?
fig, axs = plt.subplots(rank//5, 5, figsize=(15,15))
for ax, idx in zip(axs.ravel(), similar_indexes):
ax.imshow(train_images[idx], cmap='gray')
# plt.show()
111번 앵클부츠와 유사도가 높은 앵클 부츠, 스니커즈들이 유사한 아이템으로 나온다.
한 번 더해보자. 이번엔 1000번째 아이템으로.


이렇게 해서 간단한 추천 API 완성
보완하면 좋을 점
일단 추천 시스템을 학문, 기술로서 접근하면 구현에 겁이 나는데, 본 걸 만들려고 하니까 1-2시간만에 뚝딱 재미나게 만들 수 있었다. 하지만 이것은 아이템 하나에 대한 유사 아이템 추천에 불과하다. 사실 내가 플랫폼에 입장하는 순간부터 온갖 아이템들이 납득할만한 근거로 제시되는데, 이를 구현하기 위해서는 여러 알고리즘의 결과를 적절하게 통합하는 것도 필요할 듯하다. 유저-아이템-점수의 관계를 가지는 데이터를 찾아 또 다른 API를 만들어보자. 나아가 평점뿐만 아니라, 사용자의 characteristics 까지 고려하여 추천할 수 있는 방법은 뭐가 있을지도 리서치하고 구현해보자. (추천 시스템에서는 성능 좋은 모델도 중요하지만, 시스템을 구성하는 그 외 알고리즘과 알고리즘의 구성 방식이 더더욱 중요하다고 생각된다.)
'인공지능 > 추천 시스템' 카테고리의 다른 글
| [논문리뷰] CORE: Simple and Effective Session-based Recommendation within Consistent Representation Space (2) | 2023.05.20 |
|---|---|
| [논문리뷰] AutoRec: Autoencoders Meet Collaborative Filtering (3) | 2023.05.19 |
| [RecSys] 연관 규칙 (Association Rule) (0) | 2023.02.27 |
| [RecSys] 추천 시스템 개요 (0) | 2023.01.29 |
| [review] "카카오 AI추천 : 카카오의 콘텐츠 기반 필터링 (Content-based Filtering in Kakao)" 리뷰 (0) | 2023.01.02 |


